どうもY-nek0(@Ynek0)です。
最近職場でヘルプで駆り出された際についでにこれもできない?
と1番面倒くさいからみ方をされました。
依頼として『文字の中から文字を抽出したいんだよね~』と言う事。
続きの声を聞くと『毎月これの抽出に3日費やしてさ~』との事。3日!?
色々と思うところはありましたが、これを颯爽と解決し自分の評価を上げつつも
この脳死作業から解放してあげようと言う事でやりました。
要件聞きながらベストな状態になるまで20分。
これでその人の残業時間込みで30時間は短縮できており、早く家に帰れるようになりました。
自分の席へと戻る際、ふと思ってしまいました『この業務を何年続けていたのだろう』と……
ではそんな文字列抽出について説明致します。
まずもって文字と文字列の違い
まず文字と文字列の違いについて認識をあわせておきましょう
まず文字は
あ
これが文字です。1語で独立している文字です。
次に文字列です
あいうえお
この『あいうえお』と1語が連続している事を文字列といいます。
文字を取り扱う関数
では次にGoogleスプレッドシートにて文字を取り扱う関数をご紹介します。
おまけにArrayformuraで設定した場合も合わせていきますよ~
Arrayformuraとはなんぞや?と言う方はこちらをチェック!

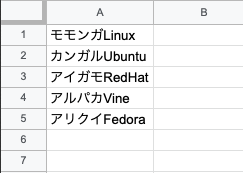
使用するデータリストはこんな感じです。
LEFT関数
文字列の最も左側から指定された数の文字を取り出す関数です。
# 1 通常version
=LEFT(文字列またはセル指定,抽出する文字数)
=LEFT(A1,4)
#2 ARRAYFORMULA version
ARRAYFORMULA(LEFT(LEFTを適用するセルの範囲,抽出する文字数))
=ARRAYFORMULA(LEFT(A:A,4))
結果
#1 通常version
『モモンガ』と出力
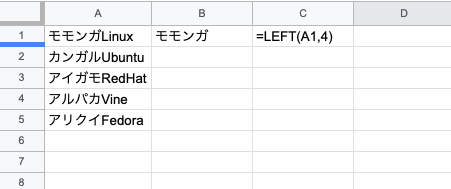
#2 ARRAYFORMULA version
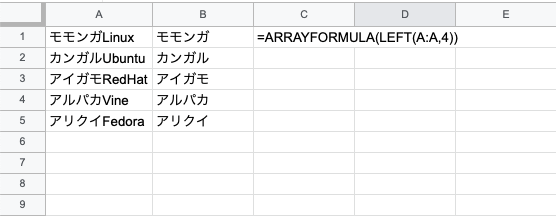
モモンガ、カンガル、アイガモ、アルパカ、アリクイ
を表示
RIGHT関数
文字列の最も右側から指定された数の文字を取り出す関数です。
# 1 通常version
=RIGHT(文字列またはセル指定,抽出する文字数)
=RIGHT(A1,5)
#2 ARRAYFORMULA version
ARRAYFORMULA(RIGHT(RIGHTを適用するセルの範囲,抽出する文字数))
=ARRAYFORMULA(RIGHT(A:A,5))結果
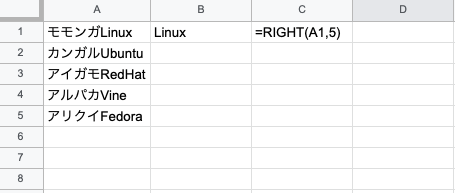
#1 通常version
『Linux』と出力
#2 ARRAYFORMULA version
Linux、buntu、edHat、カVine,edoraと出力
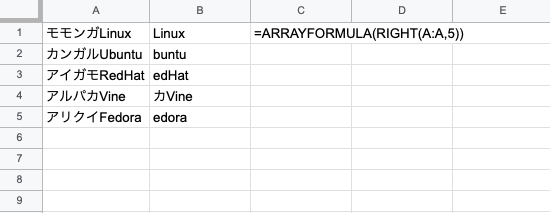
あれ?なんか表示がおかしいですね。
しかしRIGHT関数的には右から5文字の文字列を抽出しているので実際は正しい出力となります。
ただ、大体こういった場合って期待通りの出力とは言わない感じですよね。
それではちょっとだけ脱線で、どうすれば単語を全て抽出できるかって所ですが
ここは
REGEXEXTRACT関数を使っちゃいます!
この関数を使うと……
こんな事が出来ちゃうわけですよ~。
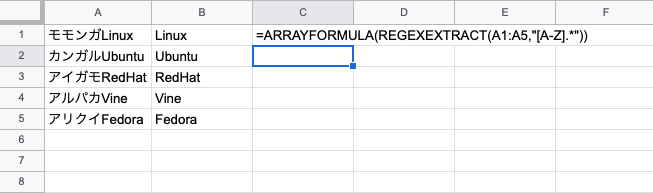
是非記事も参考にして下さい!
MID関数
文字列を指定された場所から指定された数の文字を取り出す関数です。
# 1 通常version
=MID(文字列またはセル指定,開始する文字列の位置,抽出する文字数)
=MID(A1,4)
#2 ARRAYFORMULA version
ARRAYFORMULA(MID(MIDを適用するセルの範囲,開始する文字の位置,抽出する文字数))
=ARRAYFORMULA(MID(A:A,2,3))
ここで注意ですが開始する文字の位置から1、2、3と数えるので数え間違いに注意しましょう。
結果
#1 通常version
『モンガ』と出力

#2 ARRAYFORMULA version
モンガ、ンガル、イガモ、ルパカ、リクイと出力
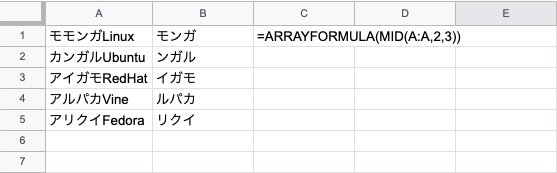
を表示
この様に使っていきます。
LEFT・RIGHT・MID関数はどの場面で利用するか
主に利用する場面は
文字列が定型化されているデータをもらった場合などに利用します。
特に銀行系のエクセルファイルなどでは銀行支店名に文字続きで銀行名があったりその後ろに10桁番号がさらに続いたりと
文字列がが定型化されている場合が多いので、そういった場合に威力を発揮してくれます。
都道府県や不定期に入ってくるアルファベットに強いのは正規表現が使えるREGEX関連の関数になるので
是非使い分けを考えて見てください!
では今回は以上です!またご贔屓に!